Ce billet de blog s’inscrit dans la série « Voyage au pays de la grosse donnée » qui cherche à voir ce qu’il est possible de faire en sciences sociales avec du traitement automatique de texte et du langage sur des volumes de données massives et parfois hétérogènes. Il n’a pas la prétention de montrer l’état de l’art dans le domaine, mais cherche à parler des difficultés que l’on peut rencontrer en s’embarquant dans ce type de recherche, pour voir quelles peuvent être les opportunités et les limites de telles méthodes pour le chercheur moyen que je suis, aux compétences en informatique limitées.
Qui a fait du lobbying sur l’article 89 du Règlement général de protection des données, qui définit le régime dérogatoire applicable aux traitements de données à caractère personnel pour des finalités de recherche [1]Une voire une catégorie d’articles sur ce sujet devrait être dédié bientôt sur mon blog. En attendant, vous pouvez aller voir le compte-rendu d’une journée d’étude organisée … Continue reading.
D’où tire-t-il sa légitimité ? Quels discours, quelles stratégies argumentatives ont été adoptées par quels acteurs pour influer sur son contenu ?
Que ce soit sur le site de la Commission européenne (documents envoyés pour une consultation publique datant de 2009), sur celui du Parlement européen (rapports parlementaires, amendements déposés, etc.) ou bien grâce au travaille des militants et militantes ayant créé le site Internet Lobbyplag, de nombreux documents relatifs à ce sujet sont disponibles.
Ces documents, sont, dans leur ensemble, au format PDF.
Pour l’instant, j’ai ainsi récupéré près de 300 documents de différentes institutions publiques, lobbies, ONG, et particuliers exprimant leurs positions sur la réforme du droit des données à caractère personnel :

Grâce à la librairie PyPDF2 il est possible de faire lire par l’ordinateur tous ces documents PDF à la recherche de certains mots-clefs (ici : science, scientific, research, data mining et big data) pour voir dans quels documents ces mots sont utilisés et même pour indiquer à quelle page on peut les trouver.
[Utile] Cela ne permet pas de faire de l’analyse automatique, mais permet de gagner beaucoup de temps dans le tri d’un corpus pertinent à une analyse qualitative classique
Voici le tableau ainsi généré :
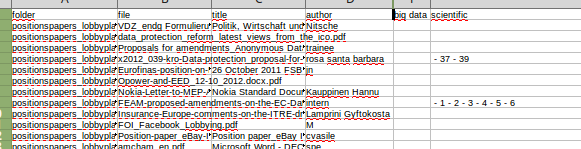 Ainsi qu’on peut le constater, certains documents ne contiennent pas le mot « scientific » et il serait alors possible d’exclure de mon corpus ces documents.
Ainsi qu’on peut le constater, certains documents ne contiennent pas le mot « scientific » et il serait alors possible d’exclure de mon corpus ces documents.
Mais bizarrement, certains documents PDF qui contiennent bien, quand je l’ouvre, le mot “scientific”, ne sont pas détectés par mon script. C’est ainsi le cas de LIBE.pdf, le rapport de la commission Libertés civiles, justice et affaires intérieures :

![]()
Pourtant, aucun message d’erreur n’avait été généré : le document semble avoir été ouvert correctement par le script. Où se situe l’erreur de lecture ? D’autres documents sont-ils affectés ? Une vérification détaillée s’impose alors, qui permet de montrer qu’en effet, PyPDF2, la librairie que j’avais utilisée, se révèle totalement incapable de lire le document PDF en question. Là où normalement je devrais obtenir ce type de résultat :
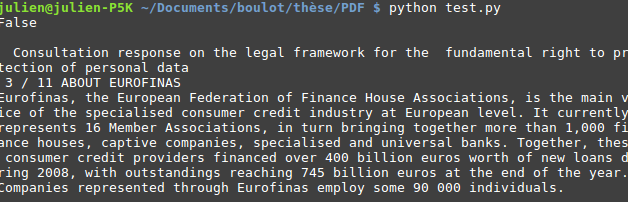
J’obtiens ceci, et ce alors même que le petit message “False” m’indique que mon PDF n’est nullement chiffré :

En poussant un peu mes tests, je me suis rendu compte que 72 documents sur 266 était affecté, soit presque un tiers (27%) de mon corpus. Un problème majeur de nature à biaiser totalement le corpus final que j’aurai à analyser.
[Problème] Certaines erreurs sont détectées par l’ordinateur. Par exemple, il peut arriver qu’un document ait pour extension “.pdf” et qu’il soit incapable de l’ouvrir car le fichier est corrompu ou bien est par exemple un fichier .doc dont l’extension a été changée par erreur. Cependant, sauf si on lui demande de vérifier en lui fournissant un dictionnaire ou une expression dont on estime qu’elle doit se trouver absolument dans le texte du PDF (j’ai utilisé dans mon corpus le terme “data” pour ce test) l’ordinateur est incapable de savoir si une chaîne de texte extraite d’un PDF signifie quelque chose pour un humain ou pas. Et il n’affichera aucun message d’erreur pour alerter l’utilisateur du programme qu’il n’a pas pu lire certains fichiers. Sans une vérification manuelle par le chercheur, des biais de sélection pouvant invalider complètement la fiabilité des résultats peuvent facilement se produire.
Que faire face à cela ? Le seul site web que j’ai trouvé qui parle du problème ne propose aucune solution avec la librairie PyPDF2. Comment se comporte une autre librairie ?
Il existe heureusement une autre librairie, PDFMiner. Et grâce à DuckPuncher de Stackoverflow.com, j’ai même pu récupérer une fonction prête à l’emploi pour effectuer l’extraction de texte du PDF. Et le miracle se produisit !

Grâce à cette autre librairie, je n’ai plus que 39 documents sur 266, soit environ 15%, qui ne contiennent même pas, selon mon script, une seule fois le mot « data ».
Certains documents PDF, comme celui-ci, résistent donc hélas même à PDFMiner :
Pour ces documents, aucun espoir, même le lecteur de PDF XReader est incapable de faire une recherche dans leur texte :

Mais sur ces 39 documents qui ne contiennent pas le mot data, certains sont en réalité rédigés dans une autre langue que l’anglais, par exemple en allemand. En enlevant ces 22 fichiers, avec un tri à la main (même s’il aurait pu être possible avec scipy de faire une détection automatique de langage) il reste 17 fichiers que PDFMiner ne sait pas lire dont 6 qui ne contiennent que des images, et 1 document qui ne contient pas le mot “data”. Donc sur 244 documents en anglais, le taux d’échec tombe à 7%. Ça reste beaucoup, mais c’est mieux que les 30% de tout à l’heure !
Il reste donc 17 fichiers à fouiller manuellement pour savoir s’ils contiennent un des mots-clefs recherchés et savoir s’il faut ou non les intégrer à notre corpus.
Quant au 227 documents en anglais lus par PDFMiner, voici combien d’entre eux contiennent les mots recherchés :
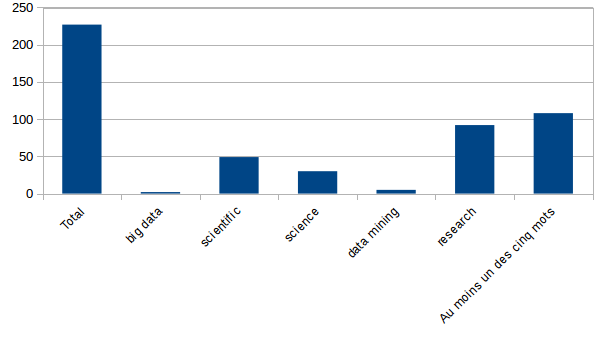 Le terme « research » a donc souvent été utilisé sans être corrélé à « science » ou « scientific ». Dans quel autre contexte a-t-il été utilisé ?
Le terme « research » a donc souvent été utilisé sans être corrélé à « science » ou « scientific ». Dans quel autre contexte a-t-il été utilisé ?
De façon étonnante, le terme « big data » n’a été utilisé que 2 fois, et « data mining » 5 fois. Est-ce à dire que les représentations politiques liées au Big Data aient été exclues du débat ? Lorsque l’on connaît de façon empirique ce terrain, on sait qu’une telle conclusion serait évidemment fausse.
Par contre c’est intéressant de noter que seuls une cinquantaine de documents contiennent le mot « scientific », sur 244, soit 21,5%.
Ce qui est pas mal, mais permet déjà de circonscrire un corpus plus restreint sur lequel concentrer une analyse qualitative de contenu.
Pour information, le script utilisé à l’origine était le suivant :
# -*- coding: utf-8 -*-
import unicodecsv as csv
import pyPdf, os, sys
if __name__ == "__main__":
list_of_dirs = os.listdir(os.getcwd())
headers = ["folder", "file", "title", "author", "date", "big data", "scientific", "science", "data mining", "research", "data"]
wordlist = ["big data", "scientific", "science", "data mining", "research", "data"]
lines = []
f = open("output.csv", "w")
writer = csv.DictWriter(f, fieldnames=headers)
writer.writeheader()
for element in list_of_dirs:
if os.path.isfile(os.path.join(os.getcwd(), element)):
print element + " is a file"
else:
print "Processing : " + element
for document in os.listdir(os.path.join(os.getcwd(), element)):
print document
input_file = pyPdf.PdfFileReader(file(os.path.join(os.getcwd(), element, document), "rb"))
words = {"big data" : "", "scientific" : "", "science" : "", "data mining" : "", "research" : "", "data" : ""}
corruptfile = False
try:
numpages = input_file.getNumPages()
corruptfile = False
except:
print "PARSE ERROR : document " + document + " is corrupt"
corruptfile = True
if not corruptfile:
for i in range(0, input_file.getNumPages()):
try:
text = input_file.getPage(i).extractText()
except:
print "PARSE ERROR : page : " + str(i+1)
text = ""
text = text.lower()
for word in wordlist:
if word in text:
words[word] = words[word] + " - " + str(i+1)
try:
title = input_file.getDocumentInfo().title
except:
title = "PARSE ERROR"
try:
author = input_file.getDocumentInfo().author
except:
author = "PARSE ERROR"
if not corruptfile :
line = {"folder" : element, "file" : document, "title" : title, "author" : author, "date" : os.path.getctime(os.path.join(os.getcwd(), element, document)), "big data" : words["big data"], "scientific" : words["scientific"], "science" : words["science"], "data mining" : words["data mining"] , "research" : words["research"] , "data" : words["data"]}
else :
line = {"folder" : element, "file" : document, "title" : "CORRUPT FILE", "author" : "CORRUPT FILE", "date" : os.path.getctime(os.path.join(os.getcwd(), element, document)), "big data" : words["big data"], "scientific" : words["scientific"], "science" : words["science"], "data mining" : words["data mining"] , "research" : words["research"], "data" : words["data"]}
writer.writerow(line)
f.close()
Le code que j’ai finalement utilisé (avec PDFMiner) :
# -*- coding: utf-8 -*-
import unicodecsv as csv
import os, sys
from datetime import datetime
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from cStringIO import StringIO
import pyPdf
#Le développement de ce script a été grandement aidé par : https://stackoverflow.com/questions/26494211/extracting-text-from-a-pdf-file-using-pdfminer-in-python
#Et notamment par la solution proposée par l'utilisateur : https://stackoverflow.com/users/2930045/duckpuncher
if __name__ == "__main__":
list_of_dirs = os.listdir(os.getcwd())
headers = ["folder", "file", "title", "author", "date", "big data", "scientific", "science", "data mining", "research", "data"]
wordlist = ["big data", "scientific", "science", "data mining", "research", "data"]
lines = []
f = open("output_pdfminer.csv", "w")
writer = csv.DictWriter(f, fieldnames=headers)
writer.writeheader()
for element in list_of_dirs:
if os.path.isfile(os.path.join(os.getcwd(), element)):
print element + " is a file"
else:
print "Processing : " + element
for document in os.listdir(os.path.join(os.getcwd(), element)):
print document
path = os.path.join(os.getcwd(), element, document)
#Begin initialising PDFMiner
rsrcmgr = PDFResourceManager()
retstr = StringIO()
codec = 'utf-8'
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams)
fp = file(path, 'rb')
interpreter = PDFPageInterpreter(rsrcmgr, device)
password = ""
maxpages = 0
caching = False
pagenos=set()
#End init PDFMiner
text = ""
text2 = ""
words = {"big data" : "", "scientific" : "", "science" : "", "data mining" : "", "research" : "", "data" : ""}
i = 1
try:
for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password, check_extractable=True, caching=caching):
interpreter.process_page(page)
text = retstr.getvalue()
text = text.lower()
for word in wordlist:
if word in text:
words[word] = words[word] + " - " + str(i)
i = i + 1
text = ""
retstr.close()
retstr = StringIO()
device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams)
interpreter = PDFPageInterpreter(rsrcmgr, device)
except:
words["big data"] = "PARSE ERROR"
fp.close()
device.close()
retstr.close()
#Some of the stuff is going to be parsed through PyPDF
input_file = pyPdf.PdfFileReader(file(os.path.join(os.getcwd(), element, document), "rb"))
try:
numpages = input_file.getNumPages()
corruptfile = False
except:
print "PARSE ERROR : document " + document + " is corrupt"
corruptfile = True
try:
title = input_file.getDocumentInfo().title
except:
title = "PARSE ERROR"
try:
author = input_file.getDocumentInfo().author
except:
author = "PARSE ERROR"
fdate = datetime.fromtimestamp(os.path.getctime(os.path.join(os.getcwd(), element, document))).strftime('%Y-%m-%d %H:%M:%S')
if not corruptfile :
line = {"folder" : element, "file" : document, "title" : title, "author" : author, "date" : fdate, "big data" : words["big data"], "scientific" : words["scientific"], "science" : words["science"], "data mining" : words["data mining"] , "research" : words["research"] , "data" : words["data"]}
else :
line = {"folder" : element, "file" : document, "title" : "CORRUPT FILE", "author" : "CORRUPT FILE", "date" : os.path.getctime(os.path.join(os.getcwd(), element, document)), "big data" : words["big data"], "scientific" : words["scientific"], "science" : words["science"], "data mining" : words["data mining"] , "research" : words["research"], "data" : words["data"]}
print line
writer.writerow(line)
f.close()
| ↑1 | Une voire une catégorie d’articles sur ce sujet devrait être dédié bientôt sur mon blog. En attendant, vous pouvez aller voir le compte-rendu d’une journée d’étude organisée il y a environ un an à l’Institut des sciences de la communication |