Ce billet de blog s’inscrit dans la série à vocation pédagogique « Voyage au pays de la grosse donnée » qui cherche à voir ce qu’il est possible de faire en sciences sociales avec du traitement automatique de texte et du langage sur des volumes de données massives et parfois hétérogènes. Il n’a pas la prétention de montrer l’état de l’art dans le domaine, mais cherche à parler des difficultés que l’on peut rencontrer en s’embarquant dans ce type de recherche, pour voir quelles peuvent être les opportunités et les limites de telles méthodes pour le chercheur moyen que je suis, aux compétences en informatique limitées.
Les coalitions de cause sont une notion développée par Paul Sabatier et Hank Jenkins-Smith (1993) [1]SABATIER, Paul et JENKINS-SMITH, Hank (coord.) (1993) Policy Change and Learning. An Advocacy Coalition Approach, Boulder : Westview Press. Une coalition de cause se définit comme un ensemble « d’acteurs issus d’organisations gouvernementales et privées variées, qui, dans le même temps,
(a) partagent un ensemble de croyances normatives et causales
(b) participent, dans un degré non-négligeable, à une activité coordonnée dans le temps.
L’ACF démontre explicitement que la plupart des coalitions n’incluront pas seulement des leaders de groupe d’intérêt, mais également des fonctionnaires d’agences publiques, des législateurs aux différents niveaux de gouvernement, des experts, et peut-être même des journalistes » (Sabatier, 1998, cité par : Bergeron, Surel et Valluy, 1998:206-207) [2]Bergeron Henri, Surel Yves, Valluy Jérôme. L’Advocacy Coalition Framework. Une contribution au renouvellement des études de politiques publiques ?. In: Politix, vol. 11, n°41, Premier … Continue reading.
L’étude des différentes coalitions de cause permet notamment d’étudier la formation des politiques publiques, et leurs évolutions au gré des controverses.
Une méthode utilisée pour cartographier les coalitions de cause consiste à interroger des acteurs actifs au sein d’un sous-système de politique publique, c’est-à-dire au sein d’un champ social dédié à la formulation et à la mise en œuvre d’une politique publique spécifique. En leur demandant avec qui ils travaillent pour formuler des propositions et contre quels autres acteurs ils doivent contre-argumenter, il est possible d’obtenir une vision d’ensemble des coalitions de cause et de leurs lignes de clivage au sein d’un sous-système de politique publique.
Mais visualiser, sous forme de réseau d’acteurs, l’ensemble des coalitions de cause, en utilisant des techniques quantitatives, demande beaucoup de temps et d’énergie.
Tout d’abord, il faut disposer de documents à partir desquels travailler. Souvent, l’accès aux position papers de lobbies ou d’institutions gouvernementales comportant des propositions rédigées d’amendement est difficile, et si certaines organisations protègent mieux l’accès à leurs documents que d’autres, il peut y avoir un biais de sélection.

Extrait d’un position paper d’Amazon sur le Règlement général de protection des données avec propositions d’amendements
Ensuite, il faut lire un à un chacun de ces documents en identifiant les positions des uns et des autres pour ensuite parvenir à classer dans un tableau les acteurs ayant des positions en commun. Cela prend du temps, mais est tout à fait faisable en se concentrant sur une ou deux dispositions spécifiques d’un texte législatif. C’est ce que j’ai fait pour cartographier les débats autour de l’article 89 du Règlement général de protection des données (RGPD) sur le régime applicable aux traitements de données personnelles à des fins de recherche scientifique [3]Voir le billet précédent sur la sélection d’un corpus de documents PDF avec Python :
Cette méthode a permis de déterminer l’existence sur ce sujet de deux coalitions de cause distinctes, l’une, médico-pharmaceutique et l’autre, structurée autour d’ONG spécialisées dans les libertés numériques (pour les décrire de façon tout à fait succinctes et superficielles), à la quasi-exclusion de tout autre acteur.
Mais ce qui est facile à faire pour un texte devient plus difficile pour un texte de loi complet, comme le RGPD.
L’idéal serait alors d’automatiser la détection de personnes proposant des mesures identiques, c’est-à-dire des amendements identiques, et de les visualiser sous forme de réseau.
Les députés européens déposent des amendements qu’il est possible d’obtenir en allant sur le site du Parlement européen [4]Voir ici pour les amendements en commission. Les propositions d’amendements des groupes d’intérêts sont parfois disponibles. C’est notamment le cas pour le RGPD grâce au travail de militants ayant mis en place le site web Lobbyplag , qui ont importé des données d’un grand nombre de sources qu’ils ont ensuite structurées dans des fichiers .json.
La structure de ces fichiers est relativement bien documentée sur la page Github de Lobbyplag.
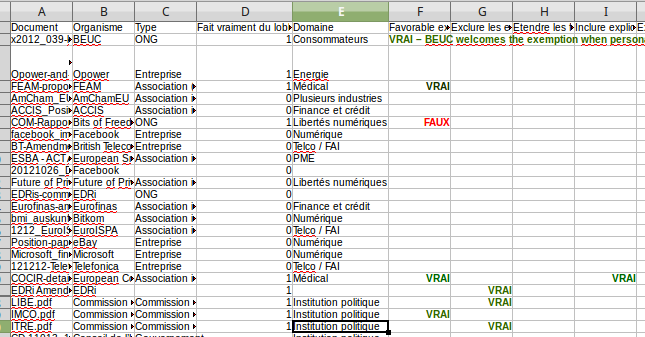
Une limite est que le nombre de documents contenant des propositions d’amendements au format PDF susceptibles d’être analysés est assez réduit. Au total, ces documents ne recouvrent que 20 organismes :
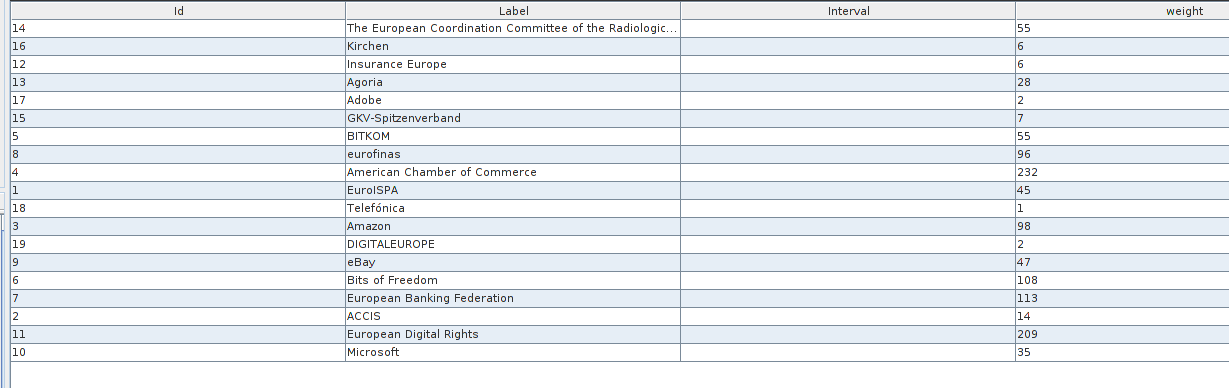
Vu les difficultés à traiter correctement les PDF de façon automatique, il n’y a rien là de bien surprenant, mais il faut avoir conscience du biais de sélection que cela entraîne, et qui d’autant plus embêtant que nous dépendons ici en entrée des données fournies par Lobbyplag, qui n’ont pas indiqué les documents qu’ils n’ont pas pu traiter, et qui eux-mêmes ne peuvent connaître la liste de l’intégralité des amendements rédigés par des groupes d’intérêts et proposés à des députés.
[Difficulté] S’il est facile d’avoir accès à l’intégralité des amendements déposés officiellement par des députés, il est impossible de recenser de façon exhaustive l’ensemble des amendements rédigés et proposés par des groupes d’intérêts. Il n’est pas même pas possible de savoir de façon certaine de quels propositions de groupes d’intérêts on ne dispose pas.
De plus, beaucoup de documents récupérés de groupes d’intérêts ne contiennent pas des amendements rédigés sous un format standard, mais des suggestions et des arguments rédigés de façon plus libre :
 Extrait d’un document du COCIR
Extrait d’un document du COCIR
Cependant, même avec toutes ces limites, le travail de Lobbyplag permet de disposer d’une liste de 1159 propositions d’amendements rédigés par des groupes d’intérêts. Parmi ces amendements, j’ai cherché ceux qui :
- Etant relatifs à un même paragraphe du texte du RGPD
- sont repris avec un texte identique à au moins 95% par un autre groupe d’intérêt
L’idée était de voir : quels groupes d’intérêts proposent les mêmes amendements ?
Dans ce corpus, il y avait 396 propositions copiées-collées d’un groupe d’intérêt à un autre (396 couples de propositions identiques à 95% ou plus).
Et voici, réalisée avec Gephi, la visualisation de quel groupe d’intérêt a copié sur quel groupe d’intérêt au moins 10 propositions :
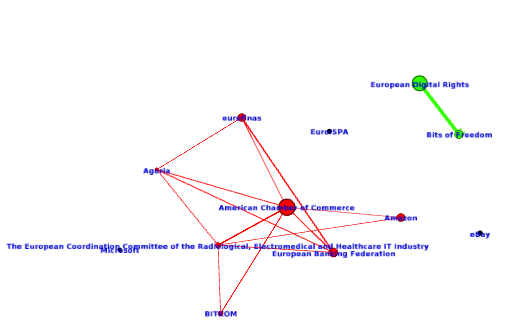
Nous voyons bien apparaître un axe « société civile » comprenant European Digital Rights et Bits of Freedom, cette dernière ONG étant membre de la première. Et à gauche, une constellation structurée autour des propositions de la Chambre de commerce US-UE, fédérant des entreprises du numérique comme Amazon, l’industrie pharmaceutique (COCIR) ou encore l’industrie du crédit financier (eurofinas).
Cependant, ce corpus est assez faible, et il n’inclut que les groupes d’intérêts. Or, avec les données récupérées depuis Lobbyplag, il est possible de faire apparaître quelles propositions d’amendements ont été reprises par des eurodéputés, et avoir ainsi une vision à plus grande échelle de la coalition de cause étudiée.
Voici le résultat d’une telle cartographie dans Gephi, avec en vert chaque amendement de député repris d’une proposition de groupe d’intérêt, les eurodéputés en bleu, et les groupes d’intérêts en jaune, la taille du cercle dépendant du nombre d’amendements proposés disponibles dans le corpus étudié :
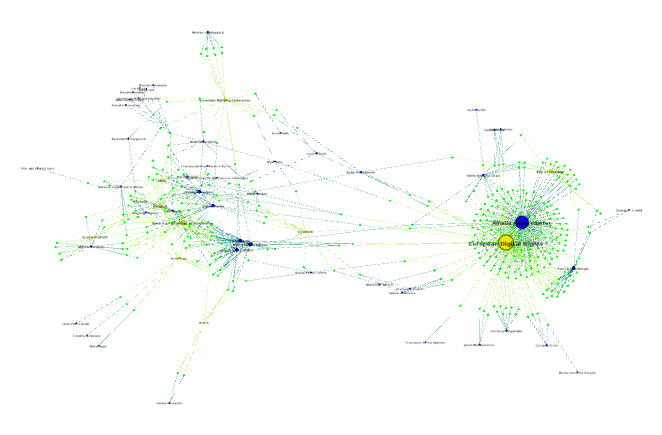
Là encore, nous voyons apparaître deux ensembles distincts : l’un structuré autour des propositions de European Digital Rights et de Bits of Freedom, et l’autre autour de divers organisations représentants des intérêts industriels :
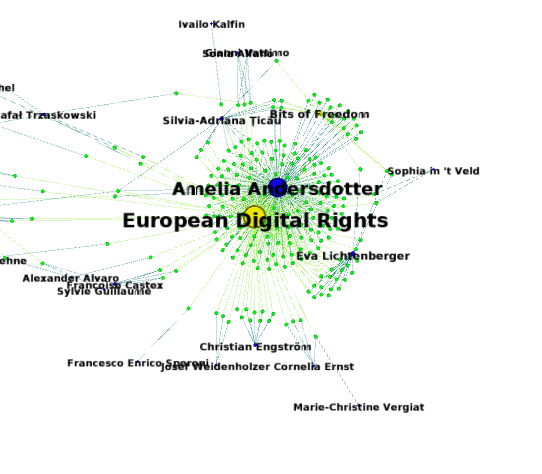
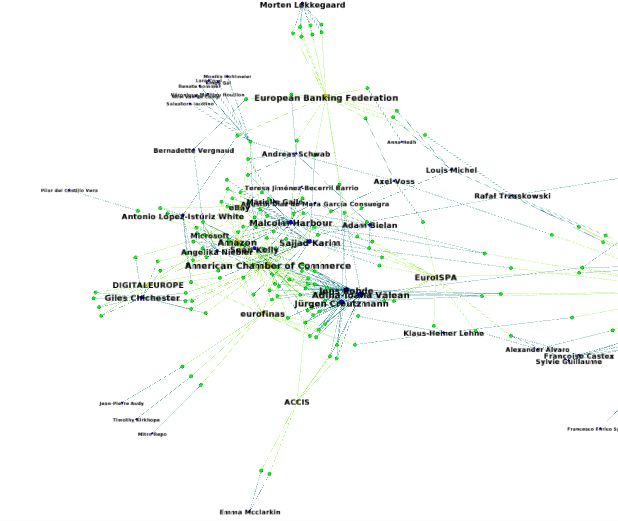
Sur cette carte, la coalition de la société civile paraît bien plus homogène que celle proche de l’industrie, mais cela a de fortes chances d’être dû au faible nombre de groupes d’intérêts issus de la société civile qui ont pu être intégrés au corpus.
La taille de ce corpus est donc insuffisante pour étudier les coalitions de cause avec un niveau de finesse plus grand que la détection de ces deux grandes coalitions opposées l’une à l’autre et répondre à la question : y a-t-il des sous-coalitions ?
Dans le cas du RGPD, grâce au travail de Lobbyplag, il a donc été possible de cartographier au moins une petite partie des coalitions de cause qui ont essayé d’influencer le résultat du processus de prise de décision du RGPD. Cela permet de visualiser les liens des certains groupes d’intérêts entre eux, et de ces groupes d’intérêts avec des députés européens. Et cela permet de faire apparaître deux coalitions de cause nettement distinctes.
[Utile] L’extraction automatique des amendements et propositions d’amendements, lorsque ceux-ci sont disponibles, couplé à un travail important de structuration de ces données sous un format à partir duquel il est possible d’en faire un traitement statistique, permet d’aboutir à une cartographie de qui reprend quelles propositions et de quels acteurs travaillent ensemble à amender un texte de loi ou, ici, un règlement européen. Cela permet de faire émerger des données des hypothèses de coalitions de cause, dont un travail plus qualitatif doit permettre de vérifier si les acteurs les composants partagent en effet des objectifs et arguments en commun.
[Limite] Une limite importante de ce travail est cependant qu’il est beaucoup plus difficile de traiter les cas où deux acteurs s’opposent par position papers interposés. Il est facile de trouver dans du texte des similarités, mais comment détecter un contre-argument de façon automatique ?
[Limite] Une deuxième limite importante est que si ce traitement quantatif et automatisé permet de cartographier qui copie ses propositions d’amendements sur qui, il n’est pas possible sans coupler cela à des méthodes qualitatives (analyse de discours, entretiens…) de comprendre pourquoi ces propositions sont faites, c’est-à-dire en fonction de quels intérêts (socialement construits) ou de quels discours et idéologies (au sens large du terme).
| ↑1 | SABATIER, Paul et JENKINS-SMITH, Hank (coord.) (1993) Policy Change and Learning. An Advocacy Coalition Approach, Boulder : Westview Press |
| ↑2 | Bergeron Henri, Surel Yves, Valluy Jérôme. L’Advocacy Coalition Framework. Une contribution au renouvellement des études de politiques publiques ?. In: Politix, vol. 11, n°41, Premier trimestre 1998. Les sciences du politique aux États-Unis. II. Domaines et actualités, sous la direction de Loïc Blondiaux. pp. 195-223. Disponible en ligne |
| ↑3 | Voir le billet précédent sur la sélection d’un corpus de documents PDF avec Python |
| ↑4 | Voir ici pour les amendements en commission |