Ce billet de blog appartient à une série destinée à raconter mes aventures dans le monde de la fouille de données et de l’analyse textuelle automatique. Mon objectif (personnel) est d’explorer par la pratique les difficultés épistémologiques et méthodologiques rencontrées dans ce type d’exercice. Mais aussi de parvenir à déterminer des cas dans lesquels de tels outils sont bel et bien utiles.
Peut-on automatiser la découverte de champs lexicaux à partir de l’analyse du champ lexical de chaque participant à une mailing-list ?
L’idée derrière la question que je me suis posée hier était que chaque participant à la mailing-list du W3C vient d’un milieu, s’intéresse à un domaine particulier plutôt qu’un autre, qui font qu’il s’intéressera plus spécifiquement à un ou plusieurs sujets en particulier au détriment d’autres. Ce qui devrait se refléter dans les mots qu’il emploie.
Du coup, au lieu que ce soit moi qui définisse par avance des champs lexicaux liés à des thématiques que j’identifie comme étant séparées et comme correspondant à des groupes d’acteurs séparés, je me suis dit qu’il serait amusant de tenter de voir si on ne pourrait pas demander à l’ordinateur de repérer des groupes d’acteurs ayant usage d’un champ lexical commun, distinct de celui d’autres groupes d’acteurs participant à la mailing-list étudiée.
L’avantage d’une telle méthode est de ne pas plaquer mes propres a priori sur ce que sont les différentes thématiques abordées (et les mots s’y rattachant), mais de voir lesquelles se dessinent en pratique à partir des traces qu’elles laissent dans les discussions.
Soit alors un tableau indiquant combien de fois chaque personne utilise chacun des mots utilisés au moins une fois sur la mailing-list public du Privacy Interest Group du W3C.
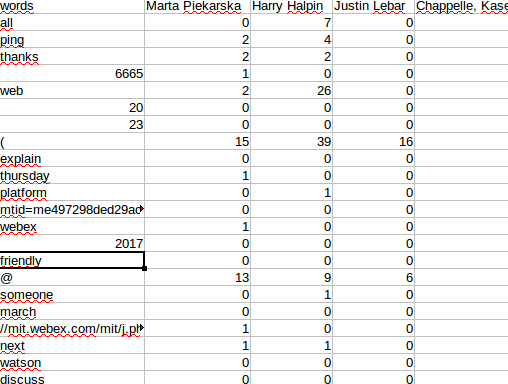
Il est alors possible, grâce à la librairie pour Python wordcloud, de générer automatiquement un nuage des mots les plus utilisés pour chaque personne, comme celui-ci :
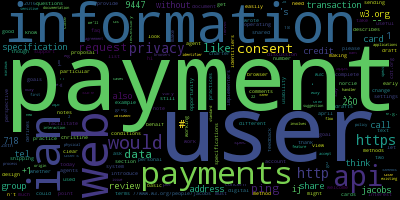
Ce nuage de mots correspond à Ian Jacobs, qui, si l’on en croit le site web du W3C, est depuis 2015 « Head of W3C Payments Activity ». Pas étonnant, alors, que son nuage de mots mette en valeur la thématique des paiements.
Le nuage de mots de Simon Rice, qui travaille pour l’autorité britannique de protection des données, contient les mots « commissioner » et « office », contenus dans le terme « Information Commissioner’s Office », qui est le nom de cette autorité :

Quant à Vincent Toubiana, spécialisé sur les questions de tracking, son nuage de mots montre l’importance qu’il accorde aux cookies et au travail du Tracking Protection Working Group du W3C :
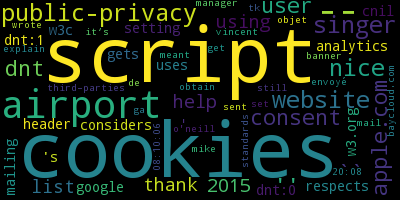
[Utile] Les nuages de mots, outre leur aspect esthétique, sont intéressants pour visualiser rapidement le champ lexical utilisé par la personne et détecter les thématiques sur lesquelles elle se spécialise. De plus, ils permettent de visualiser rapidement les différences entre le vocabulaire utilisé par deux personnes.
On pourrait donc imaginer qu’il existe des groupes de mots, des univers de thématiques communs à un groupe de personnes. Et si l’on pouvait détecter automatiquement qui a tendance à utiliser les mêmes mots, peut-être cela permettrait de créer une typologie d’acteurs. Qui parle ensemble de quoi sur la mailing-list étudiée ?
Calculons donc le coefficient de corrélation (R de Pearson) entre chaque liste de fréquence d’utilisation des mots pour chaque personne. Cela donne quelque chose comme ça :
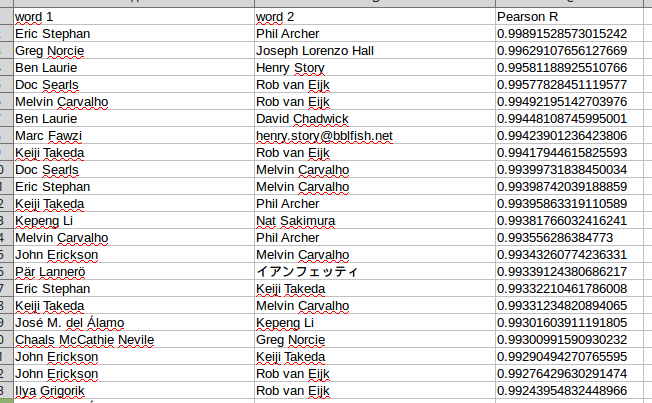
Une première chose saute aux yeux : la corrélation peut être très forte ! Et pour cause : les membres du W3C Privacy Interest Group ont, ensemble, employé 9657 mots sur leur mailing-list public-privacy. La plupart sont des mots d’usage courant, dont l’emploi varie peu d’une personne à l’autre.
[Difficulté] À ce stade, il aurait été possible – et même préférable – de limiter le calcul à un nombre limité de mots signifiants. Mais s’il est facile de supprimer de la liste les signes de ponctuation et des mots comme les dénominateurs et leurs pronoms, il existe également un grand nombre de mots dont il peut être difficile de déterminer à l’avance s’il est signifiant ou pas (par exemple certains verbes), ou s’il est utilisé par tout le monde ou bien uniquement un groupe restreint de personnes. De plus, une telle opération, à la main, peut prendre beaucoup de temps. Pour l’instant, par manque de temps, je n’ai pas encore tenté l’expérience.
Mais même avec le « bruit » généré par le fait que les mots d’usage courant soient restés dans la base, nous voyons apparaître des usages divergents chez certaines personnes :
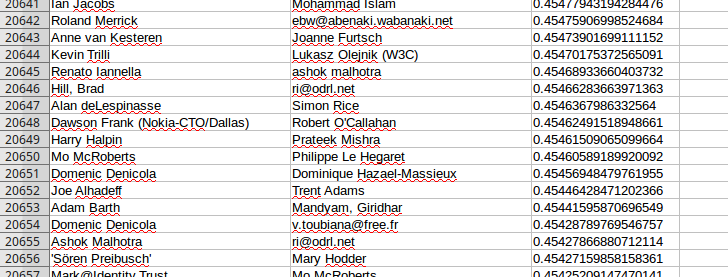
[Question à traiter] : est-ce que ces faibles corrélations entre les vocabulaires de certains usages est dû à un vocabulaire réellement différent, ou à une différence significative dans le volume de la participation de chacun, et donc dans le nombre de mots qui ont pu être utilisés en commun par chaque paire d’utilisateurs ? (Il faudrait pour cela ajouter des colonnes montrant le nombre total de mots pour chaque utilisateur, ce qui n’a pas été fait pour l’instant par manque de temps)
En modifiant un peu le fichier CSV produit par le script calculant les corrélations, il est possible de l’importer dans Gephi, un logiciel permettant de visualiser des réseaux. Ainsi, on explique à Gephi que chaque couple de noms (dans l’image ci-dessus) correspond à un lien entre deux nœuds, la force de la relation étant déterminée par le coefficient de corrélation qui a été calculé sur la base de la similitude du vocabulaire utilisé par chaque utilisateur. Pour cela, il suffit simplement de modifier l’en-tête :
Puis de dire à Gephi d’importer le fichier.
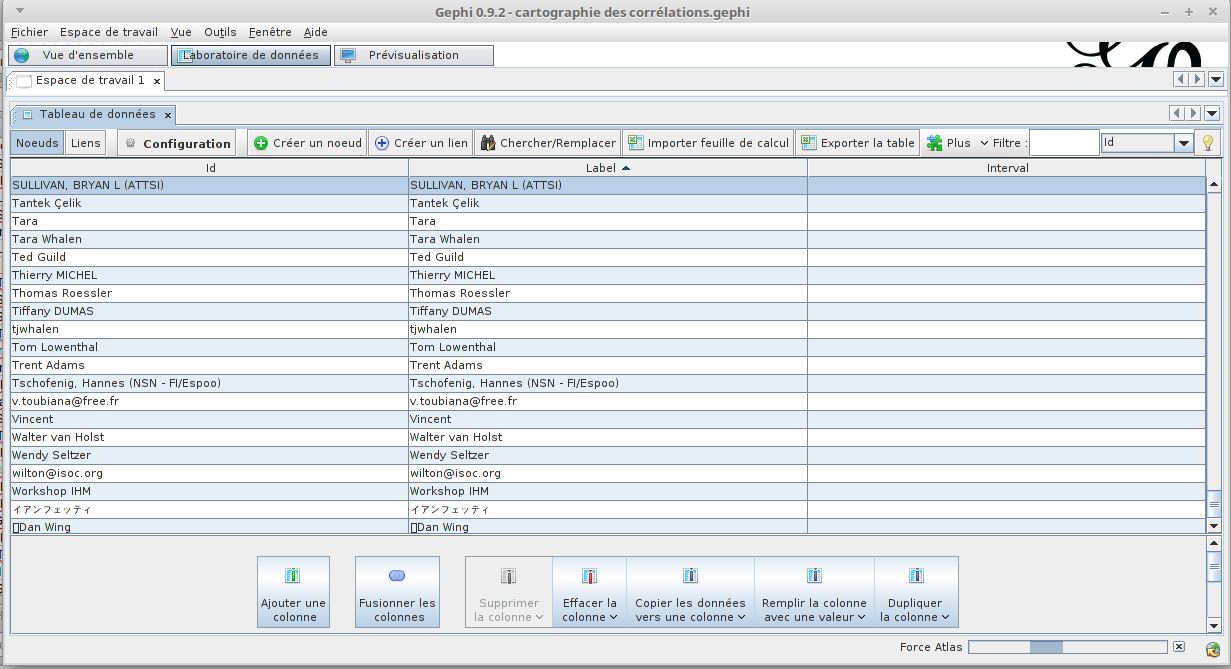
Gephi détecte automatiquement la liste complète des noms (1 nœud par nom) :
Gephi permet de faire de nombreuses visualisations différentes. Ici, la visualisation choisie est « Force Atlas ». Dans celle-ci, plus deux nœuds ont un lien fort, plus ils seront proches, et vice-versa. L’idée est ainsi de cartographier les groupes de gens ayant un vocabulaire similaire, mais distinct de celui des autres.
Voilà ce que donne cette visualisation cartographique dans Gephi :
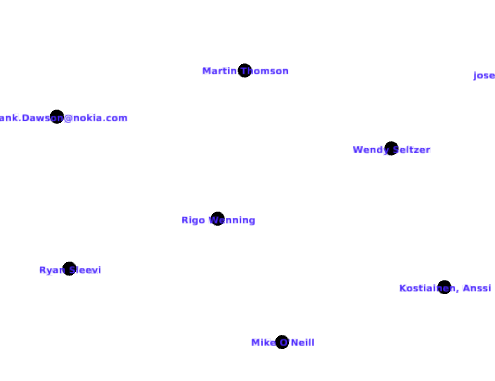
 On voit qu’il y a un grand groupe central, et quelques cas particuliers isolés. L’un d’entre eux correspond ainsi tout seulement à un utilisateur n’ayant rédigé qu’en français, alors que l’ensemble des discussions s’étaient déroulées en anglais. Il s’agit de « Workshop IHM » :
On voit qu’il y a un grand groupe central, et quelques cas particuliers isolés. L’un d’entre eux correspond ainsi tout seulement à un utilisateur n’ayant rédigé qu’en français, alors que l’ensemble des discussions s’étaient déroulées en anglais. Il s’agit de « Workshop IHM » :

Il n’est donc pas possible de séparer des groupes distincts d’utilisateurs de la mailing-list en fonction des mots qu’ils utilisent. Mais il y a bien des gens entre lesquels il existe une forte distance entre les thèmes qu’ils abordent, et qui se retrouvent à des bordures opposées du cercle central observable sur la visualisation produite par Gephi.
Prenons le cas de Prateek Mishra et de Robert Sanderson, identifiés ci-dessous sur la cartographie établie par Gephi :
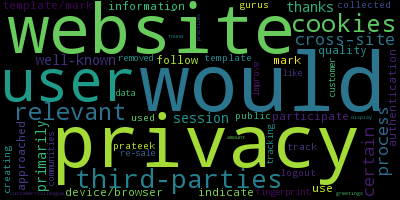 |
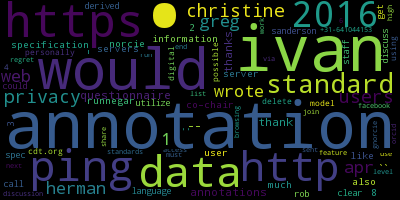 |
Le problème, c’est que deux personnes proches dans la cartographie de Gephi pourront avoir des différences importantes dans leurs nuages de mots. C’est le cas notamment de Wendy Seltzer et de Rigo Wenning. Ils sont proches, et il y a effectivement des similitudes dans leurs nuages de mots, mais aussi des différences importantes, trop importantes pour des gens aussi proches sur la cartographie établie par Gephi sur la base des données que nous lui avions fournies :
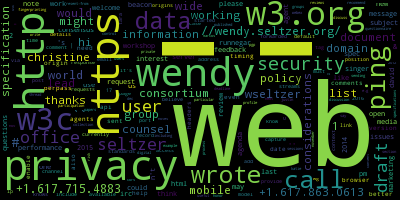 |
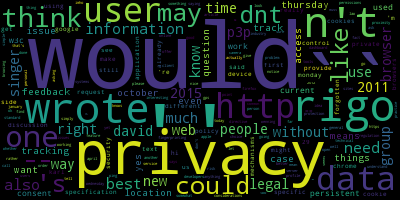 |
Cela est probablement dû au bruit de l’ensemble des mots non-signifiants dont l’usage peut être commun entre deux personnes même s’ils abordent des thématiques différentes.
Cette première exploration de la question des champs lexicaux amène à quelques premières réflexions :
- Créer automatiquement des champs lexicaux à partir de corpus de textes nécessite, si cela est possible, des techniques et des quantités de texte à analyser allant bien au-delà de ce qui a été présenté ici. En particulier, cela nécessiterait un corpus bien plus important que celui qui, justement, m’intéresse dans mon étude. Donc pour l’instant je devrai m’en passer ;
- Il semblerait, d’après les noms que j’ai repérés au centre de la cartographie générée par Gephi, qu’en tout cas sans nettoyer la liste des mots analysés de tous les mots non-signifiants, les personnes détectées comme ayant un lexique proche sont avant tout des personnes qui sont les plus actives au sein du Privacy Interest Group. Mais cela est à vérifier en testant les données quantitatives disponibles. Une possibilité pour vérifier cela visuellement serait par exemple serait de demander à Gephi de colorier en gris les noms des personnes les moins actives et en rouge le nom des personnes les plus actives (c’est-à-dire ayant envoyé le plus d’e-mails ou écrit le plus de mots).
- Malgré tout, la comparaison de nuages de mots semble une piste solide intéressante pour visualiser les centres d’intérêt de chaque participant à la mailing-list public-privacy du Privacy Interest Group du W3C, qui a été ici analysée
Mise à jour
La cartographie réalisée par Gephi de la proximité lexicale entre les contributeurs de la mailing-list a été coloriée. Les nœuds en jaune sont ceux qui représentent les participants ayant la plus faible contribution, et ceux en rouge sont les participants les plus importants.
Effectuer cette coloration de la carte permet de montrer qu’en établissant une carte rapprochant les utilisateurs ayant un usage lexical proche, sans sélectionner les mots signifiants, en réalité, on ne fait que rapprocher sur la carte les plus gros contributeurs. En effet, un grand nombre de mots courants (“all”, “the”, “a”, “be”, “have”…) forment l’essentiel du vocabulaire quelle que soit la thématique abordée. Or, plus deux personnes communiquent, plus elles auront tendance à les utiliser tous et à une fréquence finalement assez similaire.
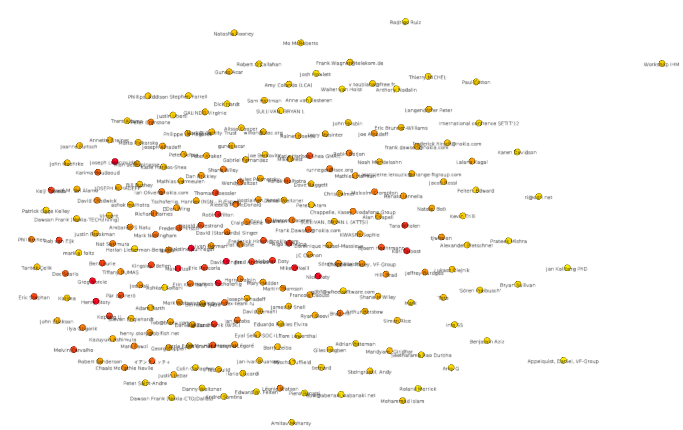
Une piste à traiter serait de voir s’il est possible de réduire cet effet en ne sélectionnant qu’un certain type de mots (par exemple : en ne sélectionnant que des noms communs).