Ce billet de blog appartient à une série destinée à raconter mes aventures dans le monde de la fouille de données et de l’analyse textuelle automatique. Mon objectif (personnel) est d’explorer par la pratique les difficultés épistémologiques et méthodologiques rencontrées dans ce type d’exercice. Mais aussi de parvenir à déterminer des cas dans lesquels de tels outils sont bel et bien utiles.
Dans un billet précédent, il avait déjà été question du fait que traiter une quantité volumineuse de données peut prendre beaucoup de temps, ce qui obligé à penser les scripts pour qu’ils soient les plus rapides possibles, et à tester de temps en temps leur vitesse d’exécution sur des petits volumes.
Cela s’avère aussi juste lorsqu’il s’agit de récupérer ces données, surtout lorsqu’elles sont copiées de pages web. Pour éviter de surcharger le serveur d’où les données sont récupérées, et pour éviter de se faire passer pour un pirate tentant une attaque par déni de service, il faut attendre un certain temps entre chaque page chargée :
![]()
Faire de la grosse donnée est donc potentiellement chronophage, même si cela dépend bien sûr de la puissance de calcul que l’on a à sa disposition.
L’objectif du présent billet n’est cependant pas de parler du temps que tout cela prend, mais de parler du temps, et plus précisément de fuseaux horaires.
[Piège à éviter] De la même façon qu’il y a sur Internet une myriade de langues et d’alphabets, avec tous les problèmes d’encodage que cela suppose et dont je n’ai pas encore parlé, il faut aussi parfois prendre en compte l’existence de plusieurs fuseaux horaires pour éviter des couacs.
Pour mes travaux de recherche, j’ai téléchargé les e-mails de la liste de diffusion du Tracking Protection Working Group du W3C. J’ai donc vérifié que le nombre d’e-mails que j’avais téléchargés correspondait bien au nombre d’e-mails mis en ligne sur le site web du W3C.
Or, quelle ne fut pas ma surprise – un tantinet paniquée puisque je ne trouvais pas l’erreur dans le script – de voir que j’avais moins de mails téléchargés sur mon ordinateur pour juin 2015 qu’il n’y en a sur le site du W3C !
| Sur mon ordinateur | Sur le site du W3C |
|
|
|
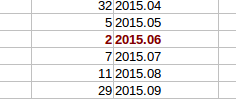

J’ai donc vérifié que ce n’était pas le vilain site du W3C qui aurait buggé …
Voici la liste des e-mails échangés en juin selon le W3C :
 A priori, il y a bien 3 mails échangés en juin.
A priori, il y a bien 3 mails échangés en juin.
Mais… si on ouvre le mail « acknowledgements (was Re: Two week review prior) » indiqué comme ayant été envoyé le 1er juin, on se rend compte que s’il l’a bien été selon le calcul du serveur du W3C (dont on ne sait pas sur quel fuseau horaire il est réglé), l’expéditeur l’a envoyé alors qu’il était, lui, encore au mois de mai, dans son fuseau horaire :
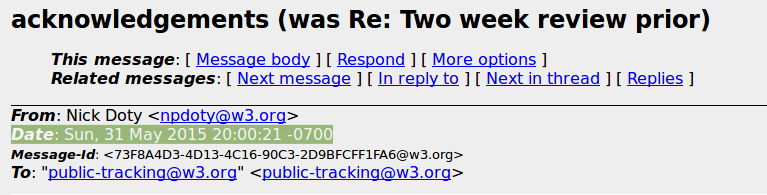
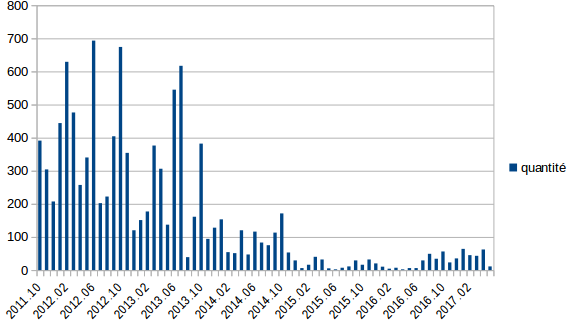
Comme mon script se base sur l’information surlignée en vert ci-dessus, il est alors parfaitement logique qu’il l’ait rangé au mois de mai … Il suffit alors de préciser, en montrant le graphe d’activité par mois de ce groupe de travail qu’il est basé sur les dates indiquées en en-tête des mails et non sur celles indiquées par le système d’archivage du W3C :